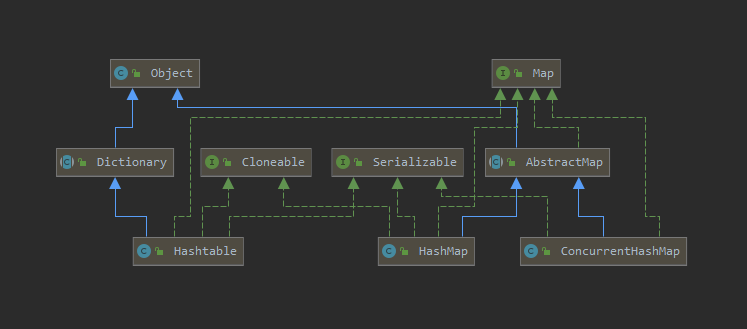
HashMap、HashTable和ConcurrentHashMap 一、接口和继承
HashMap:继承于 AbstractMap类ConcurrentHashMap:继承于AbstractMap类HashTable:继承于Dictionary类,自己实现了Map接口
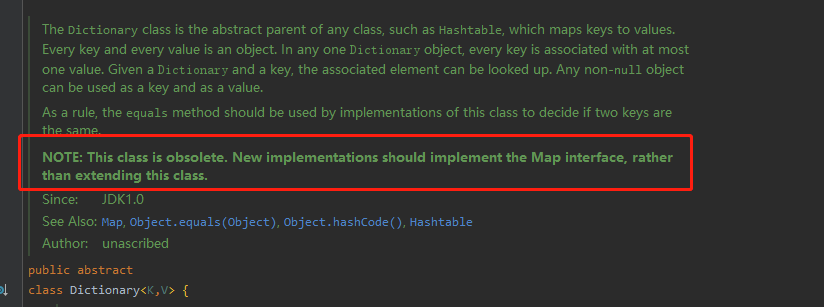
根据jdk中的注释我们可以看出Dictionary已经是一个历史遗留的集合抽象类:
注意:这个类已经过时了。 新的实现应该实现 Map 接口,而不是扩展这个类。
Hashtable类与HashMap类的作用一样,实际上,它们拥有相同的接口。与Vector类的方法一样。Hashtable的方法也是同步的。如果对同步性或与遗留代码的兼容性没有任何要求,就应该使用HashMap。如果需要并发访问,则要使用ConcurrentHashMap。
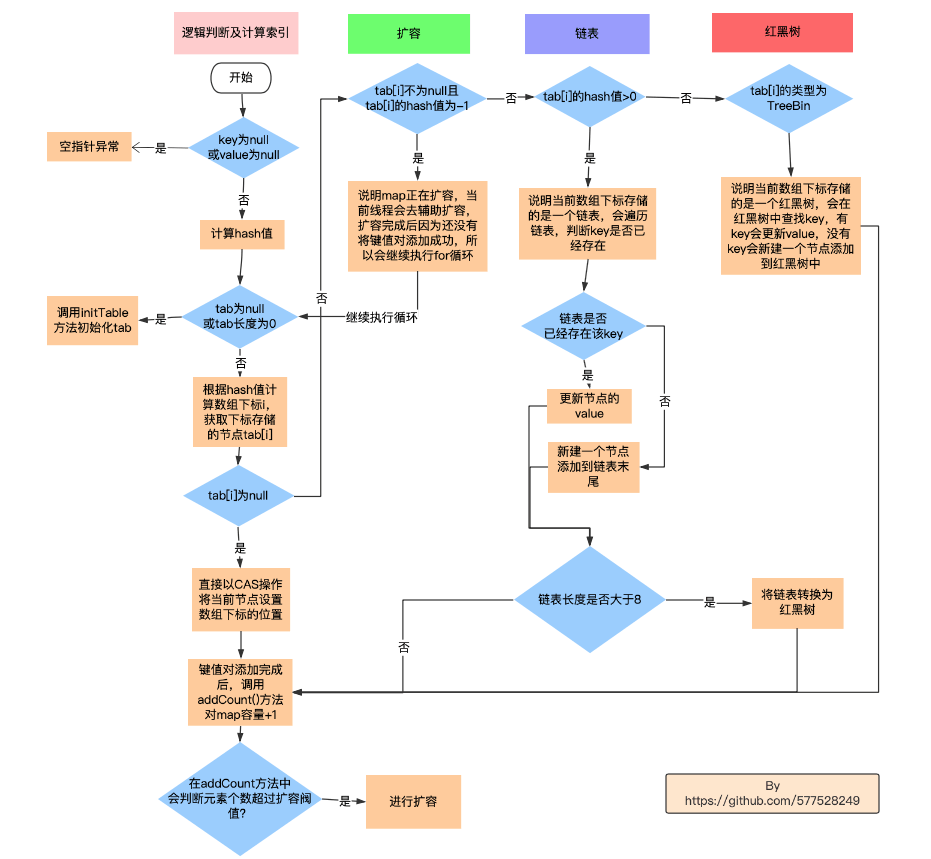
二、ConcurrentHashMap 的 put方法 1 2 3 public V put (K key, V value) { return putVal(key, value, false ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 final V putVal (K key, V value, boolean onlyIfAbsent) { if (key == null || value == null ) throw new NullPointerException (); int hash = spread(key.hashCode()); int binCount = 0 ; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 ) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { if (casTabAt(tab, i, null , new Node <K,V>(hash, key, value, null ))) break ; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null ; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0 ) { binCount = 1 ; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break ; } Node<K,V> pred = e; if ((e = e.next) == null ) { pred.next = new Node <K,V>(hash, key, value, null ); break ; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2 ; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null ) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0 ) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null ) return oldVal; break ; } } } addCount(1L , binCount); return null ; }
三、数据结构、初始化、扩容和线程安全 1. 数据结构
HashMap:数组+链表+红黑树
为了避免链表长度过长,影响查找元素的效率,当链表的长度 > 8时,会将链表转换为红黑树,链表的长度 < 6时,将红黑树转换为链表 (但是红黑树转换为链表的时机不是在删除链表时,而是在扩容时,发现红黑树分解后的两个链表 < 6,就按链表处理,否则就建立两个小的红黑树,设置到扩容后的位置)。
之所以临界点为8是因为红黑树的查找时间复杂度为logN,链表的平均时间查找复杂度为N/2,当N为8时,logN为3,是小于N/2的,正好可以通过转换为红黑树减少查找的时间复杂度 。
ConcurrentHashMap:数组+链表+红黑树
底层数据结构跟HashMap一致。只不过使用了volatile来进行修饰它的属性,来保证内存可见性
一个线程修改了这些属性后,会使得其他线程中对于该属性的缓存失效,以便下次读取时取最新的值。
Hashtable:数组+链表
底层数据结构跟HashMap类似,也是通过链地址法来解决冲突。
只是链表过长时,不会转换为红黑树来减少查找时的时间复杂度。Hashtable属于历史遗留类,实际开发中很少使用。
1 2 3 4 5 transient Node<K,V>[] table; transient volatile Node<K,V>[] table;private transient Entry<?,?>[] table;
2. 初始化和扩容
不指定初始容量
HashMap:默认16
ConcurrentHashMap:默认16
HashTable:默认11
指定初始容量
HashMap:比初始容量稍微大一些的2的幂次方大小ConcurrentHashMap:比初始容量稍微大一些的2的幂次方大小HashTable:使用初始容量
扩容
扩容时,如果原长度是N
HashMap:2NConcurrentHashMap:2NHashTable:2N+1
HashTable会扩容为2N+1,HashTable之所以容量取11,及扩容时是是2N+1,是为了保证 HashTable的长度是一个素数 ,因为数组的下标是用key的hashCode与数组的长度取模进行计算得到的,而当数组的长度是素数时,可以保证计算得到的数组下标分布得更加均匀。
HashMap和ConcurrentHashMap的hash值都是通过将key的hashCode()高16位与低16位进行异或运算(这样可以保留高位的特征,避免一些key的hashCode高位不同,低位相同,造成hash冲突),得到hash值,然后将hash&(n-1)计算得到数组下标。
3. 线程安全
HashMap:非线程安全
例如多个线程插入多个键值对,如果两个键值对的key哈希冲突,可能会使得两个线程在操作同一个链表中的节点,导致一个键值对的value被覆盖
HashTable:线程安全
主要通过使用synchronized关键字修饰大部分方法,使得每次只能一个线程对HashTable进行同步修改,性能开销较大。
ConcurrentHashMap:线程安全
主要是通过CAS操作+synchronized来保证线程安全的。
四、关于 null 值
ConcurrentHashMap和HashTable不允许 key 或 value 为 null
HashMap是非线程安全的,默认单线程环境中使用,如果get(key)为null,可以通过containsKey(key) 方法来判断这个key的value为null,还是不存在这个key。
而ConcurrentHashMap,HashTable是线程安全的, 在多线程操作时,因为get(key)和containsKey(key)两个操作和在一起不是一个原子性操作 ,可能在containsKey(key)时发现存在这个键值对,但是get(key)时,有其他线程删除了键值对,导致get(key)返回的Node是null,然后执行方法时抛出异常。所以无法区分value为null还是不存在key。
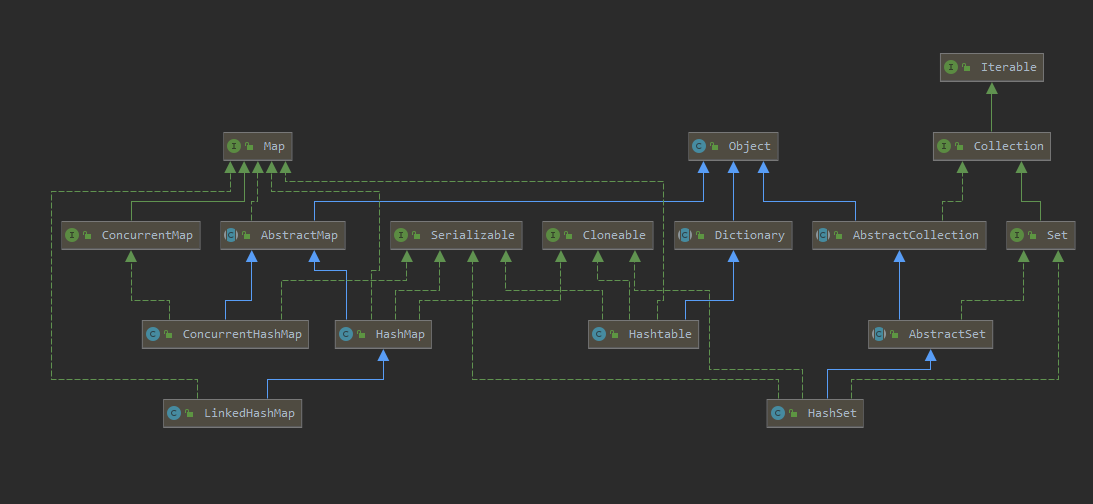
五、HashSet 和 LinkedHashMap
1. HashSet HashMap主要是用于存储非重复键值对 ,HashSet存储非重复的对象 。虽然HashMap是继承于AbstractMap,实现了Map接口,HashSet继承于AbstractSet,实现了Set接口。但是由于它们都有去重的需求,所以**HashSet主要实现都是基于HashMap的**。
如果需要复用一个类,我们可以使用继承模式,也可以使用组合模式。组合模式就是将一个类作为新类的组成部分,以此来达到复用的目的。
例如,在HashSet类中,有一个HashMap类型的成员变量map,这就是组合模式的应用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public class HashSet <E> extends AbstractSet <E> implements Set <E>, Cloneable, java.io.Serializable { private transient HashMap<E,Object> map; private static final Object PRESENT = new Object (); public HashSet () { map = new HashMap <>(); } public HashSet (Collection<? extends E> c) { map = new HashMap <>(Math.max((int ) (c.size()/.75f ) + 1 , 16 )); addAll(c); } public HashSet (int initialCapacity, float loadFactor) { map = new HashMap <>(initialCapacity, loadFactor); } public HashSet (int initialCapacity) { map = new HashMap <>(initialCapacity); } HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap <>(initialCapacity, loadFactor); } public int size () { return map.size(); } public boolean isEmpty () { return map.isEmpty(); } public boolean contains (Object o) { return map.containsKey(o); } public boolean add (E e) { return map.put(e, PRESENT)==null ; } public boolean remove (Object o) { return map.remove(o)==PRESENT; } }
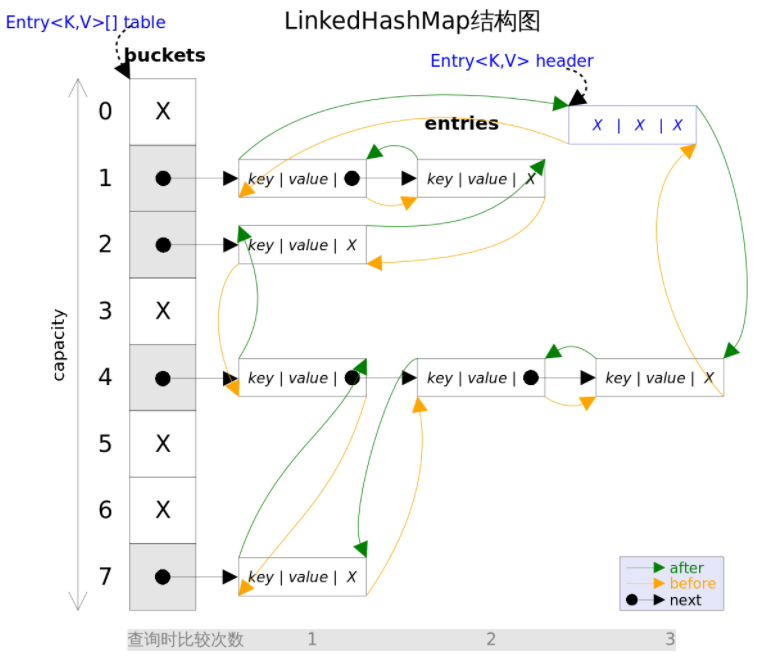
2. LinkedHashMap LinkedHashMap是HashMap的子类,与HashMap的实现基本一致,只是说在HashMap的基础上做了一些扩展:
所有的节点都有一个before指针和after指针,根据插入顺序形成一个双向链表 。默认accessOrder是false,也就是按照插入顺序 来排序的,每次新插入的元素都是插入到链表的末尾。map.keySet().iterator().next()第一个元素是最早插入的元素的key。LinkedHashMap可以用来实现LRU算法。(accessOrder为true,会按照访问顺序来排序。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void afterNodeRemoval (Node<K,V> e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null ; if (b == null ) head = a; else b.after = a; if (a == null ) tail = b; else a.before = b; } void afterNodeInsertion (boolean evict) { LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null , false , true ); } } void afterNodeAccess (Node<K,V> e) { LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null ; if (b == null ) head = a; else b.after = a; if (a != null ) a.before = b; else last = b; if (last == null ) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
根据 LinkedHashMap 实现 LRUCache 的两种方式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class LRUCache { int capacity; Map<Integer, Integer> map; public LRUCache (int capacity) { this .capacity = capacity; map = new LinkedHashMap <>(); } public int get (int key) { if (!map.containsKey(key)) { return -1 ; } Integer value = map.remove(key); map.put(key, value); return value; } public void put (int key, int value) { if (map.containsKey(key)) { map.remove(key); map.put(key, value); return ; } if (map.size() > capacity) { map.remove(map.keySet().iterator().next()); } map.put(key, value); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class LRUCache2 { int capacity; LinkedHashMap<Integer, Integer> linkedHashMap; LRUCache2(int capacity) { this .capacity = capacity; linkedHashMap = new LinkedHashMap <Integer, Integer>(16 , 0.75f , true ); } public int get (int key) { Integer value = linkedHashMap.get(key); return value == null ? -1 : value; } public void put (int key, int val) { Integer value = linkedHashMap.get(key); linkedHashMap.put(key, val); if (linkedHashMap.size() > capacity) { linkedHashMap.remove(linkedHashMap.keySet().iterator().next()); } } }
 wechat
wechat alipay
alipay









